今年もState of DevOps Reportが発表されましたね。ということで、ザザッと全体を読んで気になったところなどピックアップして読み解いてみました。
全文が気になる方は以下からPDFをダウンロードしてみてください。
cloud.google.com
今年の調査主軸
- 組織の業績
- 組織は収益だけでなく、顧客のため、さらに広範なコミュニティのために価値を生み出さなければならない
- チームパフォーマンス
- アプリケーションまたはサービスチームが価値を創造し、革新し、協力する能力
- 従業員の幸福
- 組織やチームが採用する戦略は、従業員にとって有益なものでなければならない。すなわち、燃え尽きを減らし、満足のいく仕事体験を育み、価値あるアウトプット(つまり生産性)を生み出す能力を高めることである。
今回は上記3つの成果達成に対しての調査となった。
調査結果短評
- 生成的な文化を持つチームは、組織のパフォー マンスが30%高い。
- ユーザーを重視するチーム は、組織のパフォーマンスが40%高い。
- コード レビューのスピードが速いチームは、ソフトウェアデリバリーのパフォーマンスが50%高い。
- 質の高いドキュメントが整備されている場合、質の低いドキュメントが整備されている場合に比べ、組織の業績に与 える影響が12.8倍大きくなる
- パブリッククラウドを利用す ると、クラウドを利用しない場合と比較して 、インフラの柔軟性が22%向上する。この柔軟性は、柔軟性のないインフラと比較して組織のパフォーマンスを30%向上させる。
- 組織のパフォーマンスを最大限に発揮するため には、強力なソフトウェア・デリバリー・パ フォーマンスと強力なオペレーション・パフォーマンスの両方が必要
- 過小評価されていると自認する人、女性、または自分の性別を自己表現することを選択した人は、燃え尽き症候群のレベルが高くなります。
- 過小評価されていると答えた回答者は、そうでない回答者よりも燃え尽き症候群が 24% 多くなります。
- 過小評価されていると答えた回答者は、そうでない回答者よりも 29% 多く反復的な作業を行っています。
- 女性、または自身のジェンダーを自認する人は、男性よりも 40% 多くの反復作業を行っています。
成果アンケート
組織パフォーマンスや、チームパフォーマンスなどどのくらい目標を達成できているのか?といったアンケート。
チームパフォーマンスやSLOなどは高いが、バーンアウト・AI活用・知識共有が低いのが目立っていた。
どう比較する?
グッドハートの法則とは、「計測結果が目標になると、その計測自体が役に立たなくなる」という現象です。
グッドハートの法則を無視して、「すべてのアプリケーションは年末までに『エリート』パフォーマンスを実証しなければならない」などの大まかな発言をすると、チームが指標を利用しようとする可能性が高まります。
つまり指標をハックしようとする、といったことが起こることを指し示しているのかな?
人々は、最も意味のあるものではなく、最も測定しやすいものを測定する傾向がある。
チームはユーザーのためにソフトウェアを構築し、サービスの信頼性と有用性を最終的に判断するのはユーザーです。ユーザーのニーズを重視するチームは、正しいものを構築するのに適している。
アンケート結果から見た様々なチームタイプの特徴
- ユーザー主軸のチーム
- ユーザーニーズを第一に置いたチーム。組織パフォーマンスが高い。ただし、バランス型チームよりバーンアウトが多い傾向がある。
- 機能重視のチーム
- 機能に重きを置いて、機能のデプロイメントを第一に考える。バーンアウトが最も高く、仕事への満足度やチーム/組織パフォーマンスが最も低い。
- 開発中心のチーム
- アプリケーションユーザーのニーズを優先するチーム。小規模組織に多いタイプで、ソフトウェアデリバリー/オペレーションパフォーマンスが低く、バーンアウトも高い傾向にある。
- バランス型チーム
- 全体的にバランスの取れたチーム。バーンアウトも低く、全体的な水準も高い傾向にあるが、ユーザーニーズにもう少し傾ける必要があるのかもしれない。
ユーザーを重視することが組織のパフォーマンスを予測する
組織のパフォーマンスはユーザーの理解と調整とフィードバックを繰り返すことで向上する。
ユーザーを重視することの特徴
- チームがどれだけユーザーのニーズを理解しているか
- ユーザーのニーズを満たすために、チームがどれだけ連携しているか
- 仕事の優先順位を決める際に、ユーザーからのフィードバ ックをどのように利用するか

上記はユーザー重視が組織にもたらす影響。流石に盛りすぎ感はあるが、良い効果をもたらすのはあるかもしれない。
→ 少なくとも「その改善、ユーザーにとって嬉しいものですか?ユーザーの為になっていますか?」といったミスマッチは防げるだろう
このチャプターでプラットフォームエンジニアリングについて触れられていた。
プラットフォーム・エンジニアリン グ・チームは、プラットフォームの構築に 「作れば来る」というアプローチを採用するかもしれない。しかし、より成功するアプローチは利用者である開発者を理解し、摩擦となっている問題点の特定/排除を適切に行うことなのかもしれない。
技術力がパフォーマンスを予測する
継続的インテグレーション、疎結合アーキテクチャ、コードレビュー速度の向上にリソースと労力を投資することは組織パフォ ーマンスの向上、チームパフォーマンスの向上、ソフトウェアデリバリパフォーマンスの向上、運用パフォーマンスの向上など多くの有益な結果につながる可能性がある。

AIが全然良い影響を及ぼせてないのはまだ過渡期だからだろうか?疎結合アーキテクチャへの取り組みは良い影響を出しまくっている。
次点でコードレビューの高速化も良い影響を及ぼしているが、変更のリードタイムが改善されることでコードレビューをボトルネックにしないことが大事なのか。

ここでも疎結合アーキテクチャとコードレビューの高速化が強い。
疎結合アーキテクチャの場合、変更の影響が小さいとしてもチームの他の開発者とコンフリクトを起こさないようにする必要がある。スモールバッチで作業するチームは、コンフリクトの機会を減らし、各コミットでソフトウェアがビルドされ、自動テストがトリガーされ、開発者に迅速なフィードバックが提供されるようにする。
コードレビューにかかる時間が短いチームは、ソフトウェアデリバリーのパフォーマンスが50%向上する。効率的なコードレビュープロセスはコードの改善、知識の伝達、コードの所有権の共有、チームの所有権、透明性につながる。
AIがあまり上手く作用していない点については、まだ各社がAIツールなどの組み込みに着手したばかりで、結果が出るという段階にまで至っていないだろうと綴られている。
質の高いドキュメンテーションは全体的な組織のパフォーマンス向上やバーンアウト軽減に繋がるという話。
その中で、過小評価されていると自認する人がドキュメンテーションの質とバーンアウトの増加に相関性があるという結果が出た。このグループの中で性別などによる相関性は無かったが、さらなる研究が必要であるという結びになっている。
→ 自己肯定感が薄い人にとって、ドキュメンテーションの質の維持の大変さやある種の報われなさがより辛い作業となっている要因なのだろうか?
信頼性がパフォーマンスを引き出す
SREプラクティスが組織に及ぼすパフォーマンス影響についての話。
本項独特な呼び方として、信頼性成果をオペレーショナル・パフォーマンスと呼ぶみたい。
今までと今回でのアップデートはSREの実践におけるJカーブ。今までのレポートにもあったように実践を行うことで尻上がりに信頼性が上がっていくということだったが、今年は最初は上がって停滞状態があり、また上がっていくといったグラフに変わった。
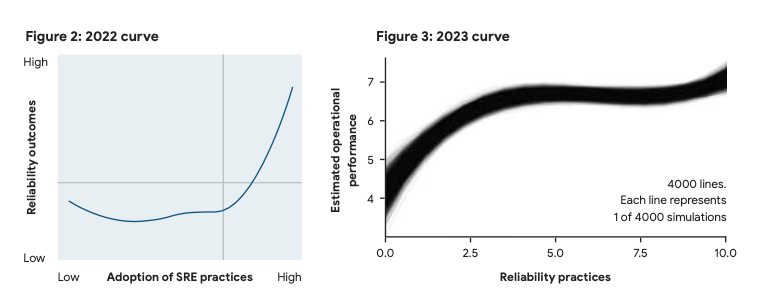
以前まではかなりSREへ投資しないと効果を得られないといった感じではあったが、少しの投資でも初期はかなりの効果を得られるのではないか?といった観点からこういったグラフになっている。停滞状態になった時点で長期的な信頼性の維持を目指した大きな投資を行うことが肝要。
SREingにおいてオンコール対応や緊急メンテナンスなどで幸福度が減るのではないか?といった懸念はあるが、実際はそれを上回るようにトイルの削減など業務遂行能力を高めていくことによってバーンアウトの低減や仕事の満足度がより高まるといった結果が出ている。
デリバリ・パフォーマンスとオペレーショナル・パフォーマンスは両方が高い水準にあることによって高いチームパフォーマンスと組織パフォーマンスが達成される。片方のみだけではダメ。
オペレーショナル・パフォーマンスを無視してデリバリ・パフォーマンスのみを追い求めたチームは組織全体の成果悪化に繋がったらしい。
SREのスケールについて語られているがスケールについてGoogleで生まれた言葉がこちら
- SREはユーザー数に対してリニアにスケールしてはならない
- SRE はユーザー数でリニアにスケールしてはならない
- SREはクラスタ数でリニアにスケールしてはならない
- SREはサービス数によってリニアにスケールしてはならない
つまり、何かを基準にスケールするように組織調整してはいけないというお話で、リニアにスケールしないと維持できない場合は成長モデルやコミュニケーション・コラボレーションなどのどこかに問題を抱えている可能性がある。
柔軟なインフラが成功の鍵
インフラの現状についてのアンケート結果が最初にあるが、
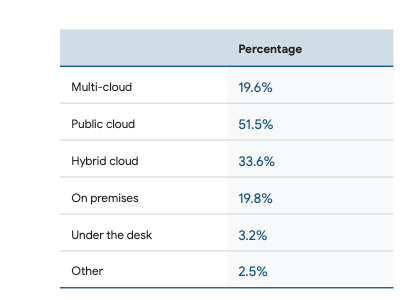
机の下が3%も・・・🤔 半数以上はクラウド利用。
クラウドの利用の初期段階ではデリバリ/オペレーショナル・パフォーマンスの低下を招く(新しい環境への適応負担など)が、クラウドを利用することによるインフラの柔軟性の高まりが期待できる。
文化への投資なしには何もかもうまくいかない
Westrumの組織類型という組織文化の分類があるらしい。
ref: https://cloud.google.com/architecture/devops/devops-culture-westrum-organizational-culture?hl=ja
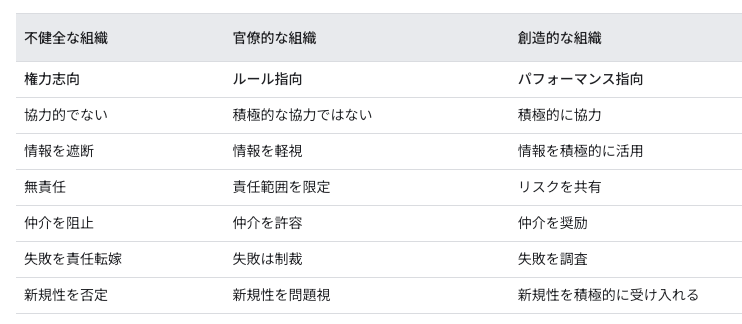
組織の文化的側面を表した一覧はこちら。
- ウェストラムの組織文化
- 組織が問題や機会にどのように対応する傾向があるか。文化には3つのタイプがある:生成的、官僚的、病的
- 組織の安定性
- 従業員にとってどれだけ安定した環境か、不安定な環境か
- 雇用の安定
- 柔軟性
- 知識の共有
- アイデアや情報が組織全体に広がる仕組み。チームメンバーは一度質問に答えれば、その情報を他のメンバーも利用でき、人々は答えを待つ必要がない
- ユーザー中心主義
- ソフトウェアを開発する際にエンドユーザーに焦点を当て、ユーザーのニーズや目標を深く理解すること。ユーザーからのシグナルは、製品やサービスをより良いものにするために利用される
仕事の配分
- チームが負担の大きい仕事をメンバー間で公平に分配するための、正式なプロセスが整備されている
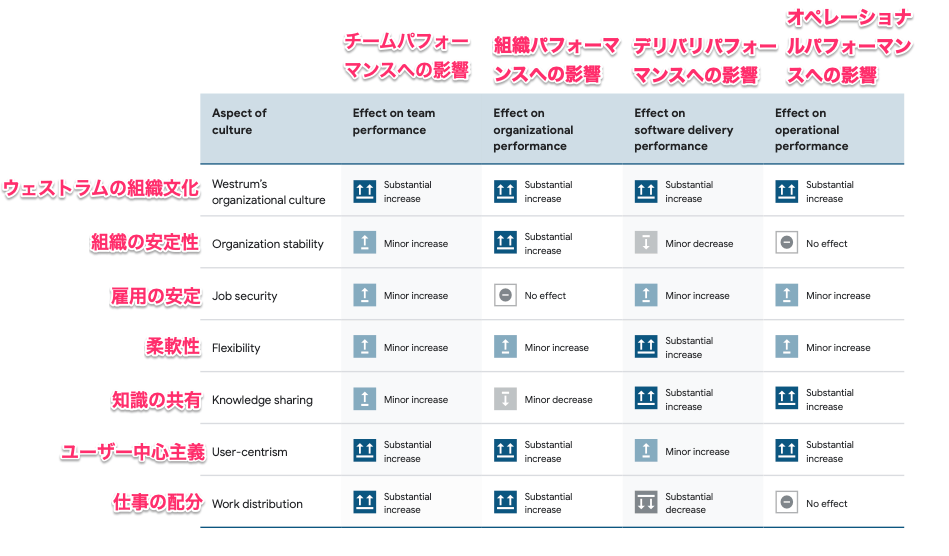
文化的側面で見てもユーザー中心主義な姿勢は良い影響を与えるというのが面白い。また、知識のサイロ化を防ぐ知識共有の文化を築けているチームはデリバリー・パフォーマンスとオペレーショナル・パフォーマンスが向上するらしい。
我々の調査結果は、優れた文化が技術的能力の向上を助けることを示唆している。
文化は実践から生まれ、実践は文化から生まれる。
文化は広範で定義が難しいが、技術的能力は通常範囲が広く、明確に定義されている。このことは、組織内の個人がどのように変化を促進させることができるかに影響を与える。
文化の醸成の成功はリーダーによるインセンティブ構造の作成でも促進させることができる。つまり、上記のような成功する側面を持つ仕組みを取り入れることを、各チームと協力しながら行うことが重要である。
いつ、どのように、そしてなぜあなたが 重要なのか?
「昇進できない仕事とは、組織にとっては重要だが、キャリアアップにはつながらない仕事である。」
こういった仕事は例えば反復的な単純作業だったりである。あまり考えたくないことだが、こういった仕事を女性が頼まれやすい状況にあり、断ることが社会的コストになるため取り掛からざるを得なくなる。
こういったジェンダー差がもたらすキャリアアップに関する問題について、"The No Club"という書籍に詳しく書かれているらしい。
ref: https://www.thenoclub.com/
過小評価されていると答えた回答者について触れていたが、こういった人たちはバーンアウトを経験する可能性が高く、それを防ぐために帰属文化の醸成が必要。何故かというと彼らは「帰属の不確実性」を感じることで過小評価されていると思うためである。
組織の一部であると帰属意識を持つことで価値が見出されていると感じるため、バーンアウトの低減につながるのである。
→ たしかに自分もSESをやっていた時に思っていたが、組織というコミュニティから外れた疎外感を感じるとバーンアウトのような意識を感じることがあった。
感想
今年も読み応えのあるボリュームで、納得感のある結果が多々ありました。SREの文脈ではオンコール対応などで幸福度が下がるかと思いきやトイルの削減などのチームの業務遂行能力を高めていくことが幸福度を上げるというのが面白い結果ではありましたね。(分かる気はする
あとはバーンアウトに関する言及が多く、人間は様々な要因でバーンアウトするということがよく分かりますね。全部のバーンアウト要因を潰すというのはまぁ無理だとは思うので、ちょっとずつでも減らしていくことが出来ればいいですね。難しいけども。
といった感じで、今回取り上げたのはほんの一部ですので是非とも全文読んでみてください〜。

")